


我們在使用 LLM 打造軟體過程中學到的經驗
涵蓋戰術、運營和戰略三個層面的 LLM 產品建設的實用指南

原文網址: https://applied-llms.org/
原文作者: Eugene Yan, Bryan Bischof, Charles Frye, Hamel Husain, Jason Liu, Shreya Shankar
現在是使用大規模語言模型(LLMs)進行產品建構的激動人心時刻。過去一年中,LLMs 已經達到了“足夠好”的水平,能夠應用於現實世界,並且每年都在變得更好和更便宜。隨著社交媒體上各種展示的增加,到2025年,預計將有2000億美元的 AI 投資。此外,供應商的 API 使 LLMs 更加可及,讓每個人(而不僅僅是機器學習工程師和科學家)都能將人工智慧融入產品中。然而,儘管進入 AI 領域的門檻降低了,創建有效的、實用的產品和系統,仍然非常困難。
我們在過去一年中的使用過程中發現了許多問題。雖然我們不敢聲稱代表整個行業,但我們希望分享我們的經驗,幫助你避免我們犯過的錯誤,並加快迭代速度。這些經驗分為三個部分:
戰術:提示、RAG、流程工程、評估和監控等實作面會需要的內容。只要你會碰觸到實際的 LLMs 建置,這部分就很適合你。
運營:關於組織的產品發佈和日常運營問題,以及如何建立有效的團隊。適合產品/技術領導者。
戰略:長期、大局觀的看法,包括“在找到產品市場契合之前不要購買 GPU”和“專注於系統而不是模型”的觀點,以及如何迭代。適合創辦人和高階管理者。
我們打算將這份指南打造成一個實用的指南,借鑒我們自己的經驗並指出實際行業中的案例,幫助你成功構建 LLM 產品。
準備好深入探索了嗎?讓我們開始吧。
1 戰術:操作 LLM 的基礎工作
在這裡,我們分享一些新興的 LLM 的最佳實踐:提升品質與可靠性的提示技巧、評估輸出的方法、增強基礎的檢索生成 (RAG) 作法、人機互動工作流程的設計等等。儘管這項技術仍持續發展中,但我們相信這些經驗是廣泛適用的,可以幫助你推出堅實的 LLM 應用。
1.1 提示
建議在設計新 LLM 應用時先從提示開始。提示的效用容易被低估同時也容易被高估。低估是因為正確的提示技巧如果使用得當,可以帶來很大的效果;高估是因為即使是基於提示的應用,也需要在提示周圍進行大量的工程才能正確運作。
1.1.1 重點在於充分利用基本的提示技巧
以下幾種提示技巧能在各種模型和任務幫助提升效果:n-shot 提示 + 上下文學習、思維鏈 (CoT) 提示、提供相關資源。
n-shot 提示 + 上下文學習的概念是為 LLM 提供輸入輸出範例,並使輸出符合我們的期望。一些建議:
如果 n 值太低,模型可能過於依賴那些特定範例,影響其面對其他情境的彈性。通常,n 值應該不低於 5。不要害怕將其提高到幾十個。
範例應該代表實際分佈。如果你正在構建電影摘要工具,請涵蓋不同類型影片的樣本,其比例應大致與實際資料中的比例相同。
你不需要總是提供輸入與輸出;僅提供輸出的範例有時就已經足夠。
如果你計劃讓 LLM 使用工具,請包含使用這些工具的範例。
在思維鏈(CoT)提示中,我們鼓勵 LLM 在返回最終答案之前解釋其思維過程。可以將其視為給 LLM 提供一個筆記本,這樣它就不必全部在記憶中完成。最初的方法是簡單地在指令中添加「讓我們一步一步思考」這句話,但我們發現讓 CoT 更具體是有幫助的,通過增加一兩句額外的提示來把 CoT 明確定義出來,通常可以顯著減少幻覺。
例如,當要求 LLM 總結會議逐字稿時,我們可以這樣提示:
首先,列出關鍵決策、後續事項和相關負責人。
然後,檢查資訊是否與逐字稿一致。
最後,將關鍵點綜合成簡明的摘要。
請注意,最近有一些研究質疑這種技術是否真的如預期那麼強大,關於使用思維鏈時推理過程中的實際情況也存在很多爭論。儘管如此,是否有效還是要實驗才知道。
『提供相關資源』是一種擴展模型知識庫、減少幻覺並增加用戶信任的強大機制。通常通過檢索增強生成(RAG)來實現,向模型提供它可以在回應中直接利用的文本片段是必要的技術。在提供相關資源時,僅僅包括它們是不夠的;不要忘記告訴模型優先使用它們,直接參考它們,並在沒有資源足夠時提及這一點。這些有助於將代理的回應根基於資源庫中的實際資料。
1.1.2 結構化你的輸入和輸出
結構化的輸入和輸出有助於模型更好地理解輸入內容,並返回可以可靠整合到下游系統的輸出。序列化格式你的輸入,可以為模型提供更多有關上下文中詞塊 (token) 之間關係的線索、特定詞塊的額外元數據(如類型),或將請求與模型訓練數據中的相似範例作連結。
例如,網路上關於撰寫 SQL 的許多問題都是從指定 SQL 結構開始的。因此,有效的 Text-to-SQL 提示應該包括結構化的結構定義。
結構化的輸入清楚地表達任務,近似於訓練數據的格式,從而增加了獲得更好輸出的可能性。結構化的輸出簡化了與系統下游的整合。Instructor 和 Outlines 在結構化輸出方面表現良好。(如果你正在導入 LLM API SDK,使用 Instructor;如果你正在導入 Huggingface 進行自託管模型,使用 Outlines。)
在使用結構化輸入時,請注意每個 LLM 系列都有其偏好。Claude 更喜歡<xml>,而 GPT 更喜歡 Markdown 和 JSON。使用 XML 時,你甚至可以通過提供 <response> 標籤來預填 Claude 的回應,例如:
messages=[
{
"role": "user",
"content": """Extract the <name>, <size>, <price>, and <color> from this product description into your <response>. <description>The SmartHome Mini is a compact smart home assistant available in black or white for only $49.99. At just 5 inches wide, it lets you control lights, thermostats, and other connected devices via voice or app—no matter where you place it in your home. This affordable little hub brings convenient hands-free control to your smart devices. </description>""" },
{
"role": "assistant",
"content": "<response><name>" }
]1.1.3 保持提示精簡,專注只做一件事
在軟體開發中,一個常見的反模式是「上帝物件」,即我們有一個單一的類別或函數來處理所有事情。這個概念同樣適用於提示。
提示通常從很簡單的內容開始:幾句指示,一兩個範例。但隨著我們嘗試提高效果並處理更多的邊緣案例,複雜性逐漸增加。更多的指示,多步推理,數十個範例。在不知不覺中,我們最初簡單的提示變成了一個兩千個詞塊的怪物。而更糟糕的是,它有可能比原來簡單提示的效果更差!GoDaddy 分享了這個挑戰,這是他們在構建 LLM 時的第一課。
就像我們努力掙扎保持我們的系統和程式碼的簡單清潔一樣,我們也應該保持提示簡潔。與其為會議記錄摘要使用一個單一的、包羅萬象的提示,我們可以將其分解成多個步驟:
提取關鍵決策、行動項目和負責人並整理成結構化格式
檢查提取的細節與原始記錄的一致性
從結構化的細節中生成簡明摘要
結果是,我們將單一的提示分解成多個簡單、專注且易於理解的提示。通過將它們分解,我們可以針對每個提示單獨進行迭代和評估。
1.1.4 打造你的上下文詞塊
重新思考並挑戰你需要提供多少上下文的假設。要像米開朗基羅一樣,去除多餘的材料,直到雕塑顯現出來。RAG 是整理所有潛在相關材料的一種流行方式,但你如何提取所需的內容呢?
我們發現,將最終傳送給模型的提示——包括所有的上下文構建、元提示和 RAG 結果——放在另一獨立頁面上閱讀,有助於你重新思考上下文。我們發現使用這種方法可以找到冗餘、自相矛盾的語言和格式不佳的部分。
另一個關鍵的優化是上下文的結構。如果你的提供的內容對人類沒有幫助,很有可能對電腦也沒幫助。仔細考慮如何構建上下文以強調各部分之間的關係,這讓資訊擷取變得簡單。
更多提示基本原理如提示的心智模型、預填充、上下文放置等。
1.2 資訊檢索生成 / RAG
除了提示之外,另一個引導 LLM 的有效方法是將知識作為提示的一部分提供。這讓 LLM 能夠基於提供的上下文進行學習,稱為檢索增強生成(RAG)。實作發現 RAG 在提供知識和改進輸出方面非常有效,且相比微調所需的努力和成本要少得多。
1.2.1 RAG 的效果取決於檢索文件的相關性、密度和細節
RAG 輸出的品質取決於檢索文件的品質,而這些品質可以從幾個因素來考量。
『相關性』是第一個也是最明顯的指標。這通常通過排名指標來量化,如 平均倒數排名 (MRR) 或 標準化折扣累積增益 (NDCG)。MRR 評估系統將第一個相關結果放置在排名列表中的能力,而 NDCG 則考慮所有結果的相關性及其位置。這些指標衡量系統在將相關文件排在前面和將不相關文件排在後面的能力。例如,如果我們檢索使用者摘要來生成電影評論摘要,我們會希望將特定電影的評論排得更高,而排除其他電影的評論。
像傳統的推薦系統一樣,檢索項目的排名對 LLM 在下游任務中的表現有很大影響。要衡量這種影響,可以運行一個基於 RAG 的任務,但將檢索到的項目隨機排序,看看 RAG 的輸出表現如何。
第二,我們還需要考慮資訊密度。如果兩個文件同樣相關,我們應該偏好更簡潔且無多餘細節的那一個。回到我們的電影例子,我們可能會認為電影劇本和所有使用者評論在廣義上都是相關的。然而,排名最高的評論和編輯評論可能會更具有更高的資訊含量。
最後是文件中提供的細節。假設我們正在構建一個 RAG 系統來從自然語言生成 SQL 查詢。我們可以僅僅提供包含欄位名稱的表結構作為上下文。但如果我們包含欄位描述和一些範例數值呢?這些額外的細節可以幫助 LLM 更理解資料結構,從而生成更正確的 SQL。
1.2.2 勿忘關鍵字搜索;將其作為基準並在混合搜索中使用
當前嵌入式(embedding-based) RAG 的知名度讓人們很容易忘記或忽視資訊檢索領域幾十年的研究和解決方案。
儘管嵌入是一種強大的工具,但它並不是萬能的。首先,雖然嵌入在捕捉高層次語義相似性方面表現出色,但它們在處理更具體的關鍵字的查詢時容易會遇到困難,例如使用者搜索名稱(如 Ilya)、縮寫詞(如 RAG)或 ID(如 claude-3-sonnet)時。像 BM25 這樣的基於關鍵字的搜索正是為此設計的。此外,經過多年的關鍵字搜索,使用者可能已經習慣了它,如果他們期望檢索到的文檔沒有返回,他們會感到沮喪。
向量嵌入並不是神奇地解決搜索問題。事實上,在語義相似性搜索之前,會有許多繁重的工作要作。要超越 BM25 或全文搜索是非常困難的。——Aravind Srinivas,Perplexity.ai CEO
我們已經向我們的客戶和合作夥伴傳達了這個信息好幾個月了。使用簡單嵌入進行最近鄰搜索會產生非常不可靠的結果,你可能最好從關鍵字為基礎的搜尋方法開始。——Beyang Liu,Sourcegraph CTO
其次,用關鍵字搜索來比較容易理解——我們可以查看與查詢匹配的關鍵字。相比之下,基於嵌入的檢索則較難解釋。最後,得益於像 Lucene 和 OpenSearch 這樣經過幾十年優化和實戰考驗的系統,關鍵字搜索通常在計算上更有效率。
在大多數情況下,混合搜索效果最好:關鍵字匹配用於明顯的匹配,而嵌入用於同義詞、上位詞和拼寫錯誤以及多模態(如圖像和文本)。Shortwave 分享了他們如何構建 RAG 管道,包括查詢重寫、關鍵字+嵌入檢索和排名。
1.2.3 處理新知識時,偏好 RAG 勝於微調 (finetuning)
RAG 和微調都可以用來將新資訊整合到 LLM 中並提高特定任務的性能。然而,我們應該優先考慮哪一種方法呢?
最近的研究表明,RAG 可能具有優勢。一項研究 將 RAG 與無監督微調(又稱持續預訓練)進行了比較,並在 MMLU 的一部分和當前事件上對兩者進行了評估。他們發現,RAG 在處理訓練期間遇到的知識以及全新知識方面,始終優於微調。在另一篇論文 中,他們將 RAG 與監督微調在農業數據集上進行了比較。同樣,RAG 對性能的提升大於微調,特別是對於 GPT-4(見表20)。
除了性能提升外,RAG 還有其他實際優勢。首先,與持續預訓練或微調相比,保持檢索索引的更新更容易且更便宜。其次,如果我們的檢索索引中有包含有毒或偏見內容的問題文檔,我們可以輕鬆刪除或修改這些有問題的文檔。可以把這看作是對於要求我們在披薩上添加膠水的文檔的緊急停止措施。
此外,RAG 中的 R 提供了更細粒度的文檔檢索控制。例如,如果我們為多個組織託管 RAG 系統,通過對檢索索引進行分區,我們可以確保每個組織只能檢索自己的索引中的文檔。這確保了我們不會無意中將一個組織的信息暴露給另一個組織。
1.2.4 長上下文模型與 RAG 不衝突
隨著 Gemini 1.5 提供高達千萬個詞塊的上下文窗口,有些人開始質疑 RAG 的未來。
我傾向於認為 Sora 大幅誇大了 Gemini 1.5 的效果。千萬個詞塊的上下文窗口基本上讓現有的大多數 RAG 框架變得不再必要——你只需將數據放入上下文中,像往常一樣與模型對話。想像一下,這對於那些大部分工程努力都集中在 RAG 的初創公司 / 代理 / langchain 項目會產生什麼影響 😅 或者用一句話來說:千萬上下文殺死了 RAG。做得好,Gemini。— Yao Fu
雖然長上下文對於分析多個文檔或與 PDF 進行對話等案例將改變遊戲的玩法,但關於 RAG 消亡的傳聞被大大誇大了。
首先,即使有千萬個詞塊的上下文大小,我們仍然需要一種方法來選擇相關的上下文。其次,除了「大海撈針」式的評估,我們尚未看到令人信服的數據表明模型可以有效地處理大上下文大小。因此,沒有良好的檢索(和排名),我們可能會讓模型被干擾信息淹沒,甚至可能用完全無關的信息填滿上下文窗口。
最後,還有成本問題。在推理過程中,Transformer 的時間複雜度隨著上下文長度線性增長。僅僅因為有一個模型可以在回答每個問題之前讀取你組織的整個 Google Drive 內容,並不意味著這是一個好主意。考慮一下我們如何使用記憶體的類比:即使技術上有可能有數十 TB 記憶體,我們仍然需要從磁碟讀取和寫入數據。
所以,即使上下文大小增長,不要急著把你的 RAG 扔掉,這種模式仍然有用。
1.3 調整和優化工作流程
提示 LLM 只是開始。為了充分發揮它們的潛力,我們的關注點需要超越單一提示,放在工作流程上。例如,我們如何將一個複雜的任務分解為多個簡單的任務?何時微調或快取有助於提高效能並降低延遲 / 成本?在這裡,我們分享經過驗證的策略和實際案例,幫助你優化並構建可靠的 LLM 工作流程。
1.3.1 按步驟進行的多輪“流程”可帶來巨大提升
拆解一個大提示為多個小提示可以獲得更好的結果這一點已經廣為人知。例如,AlphaCodium:通過從單一提示轉換為多步工作流程,他們將 GPT-4 在 CodeContests 上的準確率(pass@5)從 19% 提升到 44%。這個工作流程包括:
反思問題
從問題的公開測試進行推理
生成可能的解決方案
對可能的解決方案進行排名
生成合成測試
在公開和合成測試上迭代解決方案
具有明確目標的小任務是最好的代理或流程提示。並非每個代理提示都需要結構化輸出,但結構化輸出在與其他系統對接時非常有幫助。一些可嘗試的方法:
明確規範的計劃步驟。也可以考慮提供預定義的計劃供選擇。
將原始使用者提示重寫為代理方的提示,儘管這個過程可能會有損失!
將代理行為設計為線性鏈、DAG 和狀態機;不同的依賴和邏輯關係可能更適合不同的規模。你能否從不同的任務架構中擠出一些效果的優化?
計劃驗證;你的計劃可以包括如何評估其他代理回應的任務,以確保最終整合效果良好。
使用固定的上游狀態進行提示工程——確保你的提示針對可能發生的情境集合進行評估。
1.3.2 現階段優先考慮決定性工作流程
雖然 AI 代理可以動態回應使用者請求和環境變化,但它們的非決定性特質使得部署變得困難。代理的每個步驟都有失敗的可能性,而從錯誤中恢復的機會很低。因此,隨著步驟數量的增加,代理成功完成多步任務的可能性呈指數級下降。結果是,構建代理的團隊發現很難部署可靠的代理。
一種潛在的方法是讓代理系統生成決定性計劃,然後以結構化、可重複的方式執行。首先,根據高級目標或提示,代理生成一個計劃。然後,該計劃以決定性的方式執行。這使每一步都更可預測和可靠。其好處包括:
生成的計劃可以作為少樣本示例,用在提示或是微調代理。
決定性執行使系統更可靠,因此更容易測試和除錯。此外,可以將失敗追溯到計劃中的具體步驟。
生成的計劃可以表示為有向無環圖(DAG),相對於靜態提示更容易理解和適應新情況。
最成功的代理建造者可能是那些具有管理初級工程師經驗的人,因為生成計劃的過程類似於我們指導和管理初級工程師的方式。我們給初級工程師明確的目標和具體的計劃,而不是模糊的開放式指示,我們也應該對代理採取相同的做法。
最終,要打造可靠且有效的代理,關鍵可能在於採用更結構化和決定性的方法,同時收集數據以完善提示和微調模型。否則,我們構建的代理可能在某些時候表現出色,但平均而言,會讓使用者失望。
1.3.3 獲取更多多樣化的輸出方法
假設你的任務需要 LLM 的輸出具有多樣性。也許你正在編寫一個 LLM 管道來根據使用者之前購買的產品推薦購買你的產品目錄中的商品。當重複執行提示時,你可能會注意到結果推薦過於相似——所以你可能會增加 LLM 請求中的溫度參數。
簡而言之,增加溫度 (temperature) 參數會使 LLM 的回應更加多樣化。在取樣時,下一個詞塊的概率分佈會變得更加平坦,這意味著通常不太可能被選中的詞塊會更頻繁地被選中。即便如此,當增加溫度時,你可能會注意到一些與輸出多樣性相關的失敗模式。例如,一些來自產品目錄的適合產品可能永遠不會被 LLM 輸出。基於 LLM 在訓練期間學到的知識,某些產品可能會在輸出中被過度推薦。如果溫度過高,你可能會得到引用不存在產品(或胡言亂語)的輸出。
換句話說,增加溫度並不保證 LLM 會從你期望的概率分佈中取樣(例如,均勻隨機)。儘管如此,我們還有其他方法可以增加輸出的多樣性。最簡單的方法是調整提示中的元素。例如,如果提示模板包含一系列項目,例如歷史購買記錄,每次插入提示時隨機排列這些項目的順序可以帶來顯著的變化。
此外,保留最近輸出的一個短列表可以幫助防止重複。在我們的產品推薦示例中,通過指示 LLM 避免推薦這個最近列表中的項目,或者拒絕並重新取樣與最近建議相似的輸出,我們可以進一步多樣化回應。另一個有效的策略是改變提示中的措辭。例如,使用諸如“挑選一個使用者經常喜歡使用的產品”或“選擇一個使用者可能會推薦給朋友的產品”這樣的短語可以改變重點,從而影響推薦產品的多樣性。
1.3.4 快取的重要性被低估了
快取可以節省成本並消除生成延遲,避免對相同輸入重複運算。此外,如果回應已經過安全檢查,我們可以提供這些經過驗證的回應,減少提供有害或不當內容的風險。
一個簡單的快取方法是為處理的項目使用唯一 ID,例如我們在總結新文章或產品評論時。當請求進來時,我們可以檢查快取中是否已有摘要。如果有,則立即返回;如果沒有,則生成、檢查並提供摘要,然後將其存入快取以供未來使用。
對於更開放的查詢,我們可以借用搜索領域的技術,這些技術也利用快取來處理開放的輸入。自動完成、拼寫校正和建議查詢等功能也有助於規範使用者輸入,從而增加快取命中率。
1.3.5 何時進行微調
我們可能會遇到一些任務,即使是精心設計的提示也無法勝任。例如,即使經過大量提示工程,我們的系統可能仍然無法返回可靠、高品質的輸出。如果是這樣,那麼可能需要針對你的特定任務進行模型微調。
成功的例子包括:
Honeycomb 的自然語言查詢助手:起初,“程式設計手冊”與 n-shot 提示一起提供在提示中以進行上下文學習。儘管這種方法效果不錯,但微調模型在領域專用語言的語法和規則上產生了更好的輸出。
Rechat 的 Lucy:LLM 需要生成一種非常特定的格式,該格式結合了結構化和非結構化數據,以便前端正確渲染。微調對於其輸出的一致性至關重要。
儘管微調可能是有效的,但它也帶來了顯著的成本。我們必須標記數據,微調和評估模型,並自己運行模型。因此,需要考慮較高的前期成本是否值得。如果提示能讓你達到 90% 的效果,那麼微調可能不值得投資。但是,如果我們決定進行微調,為了減低收集人工標註數據的成本,我們可以生成並微調合成數據,或基於開源數據進行。
1.4 評估與監控
評估 LLM 是一個雷區,即使是最大的實驗室也認為這非常有挑戰性。LLM 返回的是開放式的輸出,而我們設定的任務是多樣的。儘管如此,嚴謹和周到的評估是至關重要的——OpenAI 的技術領導者從事評估工作並對個別評估給予回饋絕非巧合。
評估 LLM 應用程序時有許多觀點:可以是單元測試,或更像是可觀測性,或只是一種資料科學。這些觀點都很有用。在本節中,我們提供了一些有關打造評估和監控管道的重要經驗。
1.4.1 從實際的輸入/輸出樣本創建一些單元測試
創建單元測試,其中包含來自正式環境的輸入和輸出樣本,並根據至少三個條件對輸出進行預期。雖然三個條件看起來似乎是隨意的,但這是一個實際的起點;更少的標準可能代表你的任務定義不充分或過於開放,像個通用聊天機器人。無論是編輯提示、通過 RAG 添加新上下文,還是其他修改,這些單元測試都應該被觸發。這篇文章有一個基於測試的實際用例測試的示例。
考慮從固定詞彙是否正確存在的測試開始。也可以嘗試檢查詞語、項目或句子的數量是否在一定範圍內。對於其他類型的生成,測試可能會有所不同。基於執行的評估是一種評估程式碼生成的方法,其中你運行生成的程式碼並檢查運行時的狀態是否足夠滿足使用者請求。
例如,如果使用者要求生成一個名為 foo 的新函數,那麼在執行代理生成的程式碼後,foo 應該是可呼叫的!基於執行的評估中的一個挑戰是代理程式碼經常使運行時狀態與目標程式碼略有不同。將測試“放鬆”到任何可行答案都能滿足的最弱假設可能是有效的。
最後,以使用者的方式使用你的產品(吃自己的狗食)可以提供對真實世界數據失敗模式的見解。這種方法不僅有助於識別潛在的弱點,還提供了有用的資料樣本,可轉換為評估。
1.4.2 LLM 某種程度上可作為評審,但不是萬靈丹
使用強大的 LLM 來評估其他 LLM 的輸出,即所謂的 LLM-as-Judge,其效果有待商榷。(我們中的一些人起初也持懷疑態度。)儘管如此,當實施得當時,LLM 作為評審在與人類判斷的相關性上表現不錯,至少可以幫助建立對新提示或技術的先驗認識。具體來說,在進行成對比較(對照組 vs. 處理組)時,LLM 評審通常能夠正確判斷方向,儘管勝負的幅度可能存在雜訊。
以下是一些充分利用 LLM 評審的建議:
使用成對比較:與其要求 LLM 在李克特量表上對單一輸出進行評分,不如給它兩個選項,並要求它選擇更好的那個。這往往能夠帶來更穩定的結果。
控制位置偏差:呈現選項的順序可能會影響 LLM 的決定。為了減少這種偏差,對每個成對比較進行兩次,每次交換選項的順序。只是要確保在交換後將勝利歸因於正確的選項!
允許平手:在某些情況下,兩個選項可能同樣好。因此,允許 LLM 宣布平手,這樣它就不必隨意選擇一個贏家。
使用思維鏈:要求 LLM 在給出最終答案之前解釋其決定可以提高評估的可靠性。此外,這允許你使用一個較弱但更快的 LLM 並仍然獲得類似的結果。由於這部分流程通常是批量運行的,因此來自思維鏈的額外延遲不是問題。
控制回應長度:LLM 往往偏向於較長的回應。為了減少這種情況,確保評估的內容長度相似。
LLM 評審的一個有用應用是檢查新的提示策略是否有回歸問題。如果你有一組測試案例與其結果,有時你可以用新的提示策略重新運行這些測試案例,並使用 LLM 評審快速評估新策略可能出現的問題。
這裡有一個簡單但有效的方法來迭代 LLM 評審,我們記錄 LLM 回應、評審的意見(即思維鏈)和最終結果。然後與利害關係人一起審查這些結果以識別出可改進的地方。透過三次迭代,人類與 LLM 的一致性從 68% 提高到 94%!

儘管如此,LLM 評審不是萬靈丹。語言存在許多精妙幽微之處,即使是最強大的模型也無法可靠地評估。此外,我們發現傳統的分類器和獎勵模型可以比 LLM 評審獲得更高的準確性,同時成本和延遲更低。另外,針對程式碼生成,LLM 評審可能比直接評估執行結果的評估策略來的弱。
1.4.3 評估生成結果的『實習生測試』
我們喜歡使用『實習生測試』來評估生成結果:如果你把給 LLM 的同樣內容,包括上下文,交給相關專業的普通大學生,他們能成功完成嗎?需要多長時間?
如果答案是否定的,因為 LLM 缺乏所需的知識,請考慮如何豐富上下文。
如果答案是否定的,並且我們無法通過改進上下文來解決問題,那麼我們可能遇到了對當前 LLM 來說過於困難的任務。
如果答案是肯定的,但需要一些時間,我們可以嘗試降低任務的複雜性。任務是否可以分解?任務的某些方面是否可以模板化?
如果答案是肯定的,他們會很快完成,那麼就需深入研究資料了。模型錯在哪裡?我們能找到失敗的模式嗎?嘗試在模型回應前或回應後讓它解釋自己,以幫助你建立心理模型。
1.4.4 過度強調某些評估會損害整體性能
“當一個衡量標準成為目標時,它就不再是一個好的衡量標準。” — 古德哈特定律。
一個例子是 “大海撈針”(Needle-in-a-haystack, NIAH)評估。最初用於評估模型在上下文大小增長時的回憶能力,以及回憶 (recall) 能力如何受到 “針” 位置的影響。然而,這個評估被過度強調,以至於成為Gemini 1.5 報告的圖1。該評估方式是在一篇長文中插入特定短語(“特殊魔法{城市}數字是:{數字}”),該長文重複了 Paul Graham 的文章,然後提示模型抓取這個魔法數字。
儘管一些模型實現了接近完美的回憶能力,但 NIAH 是否真正衡量了現實應用中所需的推理和回憶能力,這點值得懷疑。考慮一個更實際的場景:給定一個小時會議的記錄,LLM 能否總結出關鍵決策和下一步措施,並正確地將每個項目歸屬於相關人員?這個任務更現實,超越了死記硬背,考慮了解析複雜討論、識別相關信息和綜合總結的能力。
這裡有一個實用的大海撈針評估的例子。使用醫生與病人對話記錄,LLM 被詢問關於病人用藥的問題。它還包括一個更具挑戰性的 NIAH,在隨機披薩配料的短語中插入,例如“製作完美披薩所需的秘密配料是:浸泡在濃縮咖啡中的椰棗、檸檬和山羊奶酪。”。在用藥任務中的回憶率約為 80%,在披薩任務中的回憶率約為 30%。
另外,過度強調 NIAH 評估會降低提取和總結任務的性能。因為這些 LLM 被微調到關注每一句話,它們可能會開始將無關細節和干擾項視為重要,從而將它們包含在最終輸出中(而這是不應該的!)
這也適用於其他評估和案例。例如,總結。如果強調事實一致性,可能會導致總結變得不夠具體(因此不太可能事實不一致),甚至不相關。相反,強調寫作風格和優雅可能會導致使用更華麗的、類似營銷的語言,導致結果偏離事實。
1.4.5 簡化標註為二分法或成對比較
對模型輸出提供開放式回饋或按李克特量表評分對認知負擔非常大。這導致所收集的數據會因評分者之間的差異而更為雜亂,因而不太有用。更有效的方法是簡化任務並減少標註者的認知負擔。兩種效果良好的方式是二分法以及和成對比較法。
在二分法中,標註者需要對模型的輸出做出簡單的“是”或“否”的判斷。他們可能被問到生成的摘要是否與原始文件事實一致,或建議的回應是否相關,或是否包含有害內容。與李克特量表相比,二分法更明確,評分者之間的一致性更高,並且有更快的處理速度。這就是Doordash 如何通過一系列是非問題來設置他們的標記佇列來標記菜單品項的方法。
在成對比較中,標註者會看到一對模型回應,並被問到哪一個更好。因為對人類來說,比起對 A 或 B 個別評分,說“A 比 B 好”要更容易,所以這會導致比李克特量表更快且更可靠的標註。在一個Llama2 見面會上,Llama2 論文的作者之一 Thomas Scialom 確認成對比較比收集監督微調數據(如書面回應)更快更便宜。前者的成本為每單位 3.5 美元,而後者的成本為每單位 25 美元。
如果你正在編寫標註指南,這裡有一些來自 Google 和 Bing 搜索的範例指南。
1.4.6 (無參考)評估和防護措施可以互換使用
防護措施有助於捕捉不當或有害內容,而評估有助於衡量模型輸出的品質和準確性。如果你的評估是無參考的,它們也可以作為防護措施使用。無參考評估是指不依賴“黃金”參考(例如人工書寫的答案)的評估,僅根據輸入提示和模型的回應來評估輸出品質。
一些例子包括摘要評估,我們只用輸入文件評估摘要在事實一致性和相關性方面的表現。如果摘要在這些指標上的得分較低,我們可以選擇不向使用者顯示它,也就是把評估作為防護措施。同樣,無參考翻譯評估可以在不需要人工翻譯參考的情況下評估翻譯品質,這也是用作防護措施。
1.4.7 LLMs 會在不應該生成輸出的時候生成輸出
使用 LLMs 的一個主要挑戰:它們經常會在不應該生成輸出的時候生成輸出。這可能會導致無害但無意義的回應,或更嚴重的如有害或危險的內容。例如,當被要求從文檔中提取特定屬性或元數據時,LLM 可能會自信地返回即使實際上不存在的值。或者,模型可能會用非英文語言回應,因為我們在上下文中提供了非英文文檔。
提示 LLM 返回“不適用”或“未知”的回應並不可靠。即使可以使用 logprobs,也不是那麼的可靠。logprobs 僅表明某個詞塊出現在輸出中的可能性,不一定代表生成內容的正確性。對於訓練以產生答案、相關內容的模型來說,logprobs 並非那麼準確。因此,雖然高 logprobs 可能代表輸出流暢且連貫,但這並不意味著它是準確或相關的。
細心的提示工程在某種程度上可以幫助解決這個問題,但我們應該輔以強大的防護措施來檢測和過濾 / 重新產生不理想的輸出。例如,OpenAI 提供了一個內容審核 API,可以識別不安全的回應,如仇恨言論、自我傷害或性內容。同樣,有許多用於檢測個人身份信息的包。防護措施的一個好處是,它們沒有特定案例的限制,可以廣泛應用於指定輸出語言的處理。此外,通過精確的檢索,我們的系統可以在沒有相關文檔時以確定性地方式回應 “我不知道”。
由此推論,LLMs 可能會在預期生成輸出的時候未能生成輸出。這可能由於各種原因,如 API 提供者的極小機率下的長延遲,或輸出被內容審核過濾器阻止。因此,持續記錄輸入和(可能缺失的)輸出對於除錯與監控非常重要。
1.4.8 幻覺是一個棘手的問題
模型花了許多關注來處理內容安全或 PII 缺陷,因此已經很少發生,而事實不一致的問題則極為頑固且更難檢測。它們的發生率落在 5% - 10%,根據我們從 LLM 供應商那裡了解到的情況,即使在簡單如摘要的任務,也很難將其降低到 2% 以下。
為了解決這個問題,我們可以結合提示工程(生成的上游)和事實不一致防護措施(生成的下游)。對於提示工程,像思維鏈(CoT)這樣的技術通過讓 LLM 解釋其推理來幫助減少幻覺,然後再返回最終輸出。接著,我們可以應用一個事實不一致防護措施,來評估摘要的真實性並過濾或重新生成幻覺。在某些情況下,幻覺是可以用確定性的方法來檢測到的。當使用來自 RAG 檢索的資源時,如果輸出是結構化的並且有明確的資源辨識度,你應該能夠手動驗證它們是否來自輸入上下文。
2 運營:日常作業和組織層面考量
2.1 資料
就像食材的品質決定了一道菜的味道一樣,輸入資料的品質也限制了機器學習系統的性能。此外,輸出的資料是判斷產品是否正常運行的唯一方法。我們所有作者都專注在資料上,每週花幾個小時查看輸入和輸出的資料,以更好地了解其分佈:模式、邊界情況以及模型的局限性。
2.1.1 檢查開發與正式環境間的差異
傳統機器學習管道中的一個常見錯誤來源是訓練-服務偏差。這發生在訓練中使用的資料與模型在正式環境中遇到的資料不同時。儘管我們在沒有訓練或微調的情況下使用 LLMs 不需要訓練集,但在開發與正式環境的測試資料偏差方面會出現類似問題。基本上,我們在開發過程中測試系統的資料應該與系統在正式環境中的資料相似。若非如此,我們可能會發現正式環境中的準確性受到影響。
環境間的偏差可以分為兩種類型:結構性和基於內容的偏差。
結構性偏差包括格式差異問題,如 JSON 字典中帶有列表類型值與 JSON 列表之間的差異、不一致的大小寫、拼寫錯誤或句子片段等錯誤。這些錯誤可能會導致模型性能不可預測,因為不同的 LLM 在特定資料格式上進行訓練,提示對細微變化可能非常敏感。
基於內容的偏差指的是資料的含義或上下文之間的差異。如同傳統的機器學習,定期測量 LLM 輸入/輸出結果的偏差是有用的。像輸入和輸出長度或特定格式要求(例如 JSON 或 XML)這樣的簡單指標是追踪變化的簡單方法。對於更“高級”的偏差檢測,可以考慮對輸入/輸出的 embedding 作 clutering,以檢測語義偏差,例如使用者討論話題的轉變,可能代表他們正移動到模型未接觸過的領域。
在測試變更時,例如提示工程,確保測試的資料集是最新且反映最新的使用者互動類型。例如,如果正式環境中的輸入常見到錯字,這些錯字也應該存在於測試資料中。除了量化的偏差測量之外,對輸出進行值化評估也是有益的。定期審查模型的輸出——俗稱“氛圍檢查”——確保結果符合預期並且符合使用者需求。最後,將不確定性納入偏差檢查也是有用的——通過對測試資料集中的每個輸入多次運行並分析所有輸出,我們有更高機率捕捉到偶爾出現的異常。
2.1.2 每天取樣查看 LLM 輸入和輸出
LLMs 是動態且不斷演變的。儘管它們具有令人印象深刻的零樣本能力和令人滿足的輸出,但它們的失敗模式可能是高度不可預測的。對於自訂任務,定期審查資料樣本對於建立對 LLMs 表現的直觀理解至關重要。
正式環境中的輸入-輸出資料是 LLM 應用的 “實地考察”(genchi genbutsu),無法被替代。最近的研究 強調了開發人員對“好”與“壞”輸出的看法會隨著他們與更多資料的互動而發生變化。雖然開發人員可以事先提出一些評估 LLM 輸出的條件,但這些事先定義的條件通常是不完整的。例如,在開發過程中,我們可能會更新提示,以增加良好回應的概率並降低壞回應的概率。這種評估、重新評估和條件更新的迭代過程是必要的,因為在不直接觀察輸出的情況下,很難預測 LLM 的行為或人類的偏好。
為了有效管理這一過程,我們應該記錄 LLM 的輸入和輸出。透過每天檢查這些日誌的樣本,我們可以快速識別和適應新的模式或失敗模式。當我們發現一個新問題時,可以立即針對它編寫一個測試或評估。同樣,對失敗模式定義的任何更新都應反映在評估標準中。這些“氛圍檢查”幫助我們識別不好的輸出;我們透過程式碼和測試使它們更加具體。最後,這種態度必須被常態化,例如將輸入和輸出的審查或標註添加到輪值任務中。
2.2 使用模型
透過 LLM API,我們只需少數供應商即可提供 AI 服務。儘管這是一個優勢,但這些依賴也涉及性能、延遲、吞吐量和成本上的權衡。此外,隨著更新、更好的模型幾乎每月出現一次,我們應該在淘汰舊模型並遷移到新模型時同時更新自己的產品。在本節中,我們分享了使用自己無法完全控制的技術的經驗,並且這些技術中的模型無法自行架設與控制。
2.2.1 生成結構化輸出以簡化下游集成
大多數的現實情況,LLM 的輸出將透過某種機器可讀格式被下游應用消費。例如,房地產 CRM Rechat 需要結構化的回應來讓前端呈現對應的小工具。同樣,Boba 是一個生成產品策略想法的工具,需要具有標題、摘要、可信度評分和時間範圍字段的結構化輸出。最後,LinkedIn 分享了關於 限制 LLM 生成 YAML 的經驗,這些 YAML 用於決定使用哪種技能以及提供調用技能的參數。
這種應用模式是 Postel 法則的一個極端版本:在接受(任意自然語言)時要寬容,在發送(類型化的機器可讀對象)時要保守。因此,我們預計它將非常耐用。
目前,Instructor 和 Outlines 是從 LLM 中產出結構化輸出的標準。如果你使用的是 LLM API(例如,Anthropic、OpenAI),請使用 Instructor;如果你使用的是自託管模型(例如,Huggingface),請使用 Outlines。
2.2.2 將提示遷移到不同模型是一件麻煩事
有時,我們精心設計的提示在一個模型上效果極佳,但在另一個模型上卻效果不佳。這種情況可能發生在我們在不同模型提供者之間切換時,也可能發生在我們跨版本升級同一模型時。
例如,Voiceflow 發現,從 gpt-3.5-turbo-0301 遷移到 gpt-3.5-turbo-1106 導致其意圖分類任務的性能下降了 10%。(幸運的是,他們有評估!)同樣,GoDaddy 觀察到了一個正向的趨勢,即升級到 1106 版本後,縮小了 gpt-3.5-turbo 和 gpt-4 之間的性能差距。(或者,如果你是個樂觀的人,可能會對 gpt-4 的領先優勢在新升級中被削弱感到失望)
因此,如果我們必須將提示遷移到不同模型,請預計這將比簡單地更換 API 端點花費更多時間。不要假設使用相同的提示會產生類似或更好的結果。此外,可靠的自動化評估有助於衡量遷移前後的任務性能,並減少手動驗證所需的工作量。
2.2.3 固定你的模型版本
在任何機器學習管道中,“改變任何一個東西就會改變所有東西” (Changing Anything Changes Everything, CACE)。而我們依賴於像大型語言模型(LLMs)這樣的組件,我們自己並不掌控這些,而且可能在我們不知情的情況下發生變化。
幸運的是,許多模型提供商提供了“固定”特定模型版本的選項(例如,gpt-4-turbo-1106)。這使我們能夠使用特定版本的模型,確保它們保持不變。在正式環境中固定模型版本可以幫助避免模型行為的意外變化,這些變化可能導致客戶投訴,如輸出過於冗長或其他無法預見的失敗。
此外,考慮維護一個與你的正式環境相似的影子管道,但使用最新的模型版本。這樣可以安全地進行新版本的實驗和測試。一旦你驗證了這些新模型輸出的穩定性和品質,你就可以自信地更新生產環境中的模型版本。
2.2.4 選擇能完成任務的最小模型
在開發新應用時,使用最大的、最強大的模型是一種誘惑。但一旦我們確定任務在技術上是可行的,就值得實驗看看較小的模型是否能達到相似的效果。
較小模型的好處是延遲和成本較低。雖然它可能較弱,但像思維鏈(chain-of-thought)、n-shot 提示和上下文學習這樣的技術可以幫助較小的模型發揮超出其本身的作用。除了 LLM API,對我們的特定任務進行微調也可以幫助提高性能。
綜合來看,針對較小模型的精心設計的工作流程往往可以匹配甚至超越單一大型模型的效果,同時速度更快、成本更低。例如,這條tweet 分享了一些資料,展示了 Haiku + 10-shot 提示如何超越零樣本的 Opus 和 GPT-4。從長遠來看,我們預計會看到更多使用較小模型的流程工程的例子,這是輸出品質、延遲和成本的最佳平衡。
另一個例子是簡單的分類任務。像 DistilBERT(6700萬參數)這樣的輕量級模型是一個驚人的強大基準。400M 參數的 DistilBART 是另一個很好的選擇——當在開源資料上進行微調時,它可以以 0.84 的 ROC-AUC 識別幻覺,超過大多數 LLM,延遲和成本不到其 5%。
重點是,不要忽視較小的模型。雖然把一個龐大的模型應用於每個問題很容易,但通過一些創意和實驗,我們通常可以找到更高效的解決方案。
2.3 產品
雖然新技術帶來了新的可能性,但構建優秀產品的原則是不變的。因此,即使我們是第一次解決新問題,也不必在產品設計上重新發明輪子。將我們的 LLM 應用開發建立在扎實的產品基礎上,可以為我們服務的對象提供真正的價值。
2.3.1 早期且頻繁地參與設計
擁有設計師會促使你深入理解和思考你的產品如何構建和呈現給使用者。我們有時將設計師刻板印象化,認為他們只是讓事物變得漂亮的人。但除了使用者界面之外,他們還會重新思考如何改善使用者體驗,即使這意味著打破現有的規則和範式。
設計師專精於用各種形式觀察與定義使用者需求。其中一些形式比其他形式更易於解決,AI 解決方案面對不同的形式的需求有不同的合適程度。與許多其他產品一樣,打早 AI 產品應該以解決的問題為核心,而非驅動它們的技術。
問問自己:“使用者希望這個產品為他們完成什麼工作?這項工作是聊天機器人擅長的嗎?自動完成如何?也許需要不同的東西!” 考慮現有的設計模式 以及它們與待完成工作的關係。這些都是設計師為你的團隊能力增添的寶貴資產。
2.3.2 使用者體驗加入人類參與
獲取高品質標註的一種方法是將人機循環(Human-In-The-Loop, HITL)整合到使用者體驗(UX)中。通過讓使用者輕鬆提供回饋與修正,我們可以改善輸出並收集有價值的數據以改進模型。
想像一個使用者上傳和分類產品的電子商務平台。我們可以設計多種 UX:
使用者手動選擇正確的產品類別;LLM 定期檢查新產品並在後端糾正分類錯誤。
使用者根本不選擇任何類別;LLM 定期在後端分類產品(可能有錯誤)。
LLM 即時建議產品類別,使用者可以根據需要驗證和更新。
雖然這三種方法都涉及 LLM,但它們提供的 UX 非常不同。第一種方法將初始負擔放在使用者身上,LLM 作為後處理檢查。第二種方法對使用者來說零負擔,但不提供透明度或控制。第三種方法則達到了平衡:通過讓 LLM 事先建議類別,減少了使用者的認知負擔,他們不必學習我們的分類體系來分類他們的產品!同時,審查和編輯建議讓使用者可以對產品分類有決定權。附加的的好處是,這創建了一個模型改進的回饋迴圈。好的建議被接受(正面標籤),壞的建議被改正(負面隨後是正面標籤)。
這種建議、使用者驗證和資料收集的模式可在許多個應用中見到:
程式碼助手如 Copilot:使用者可以接受建議(強正面),接受並調整建議(正面),或忽略建議(負面)
Midjourney:使用者可以選擇升級並下載圖像(強正面),變更圖像(正面),或生成一組新圖像(負面)
聊天機器人:使用者可以對回應提供點讚(正面)或倒讚(負面),或在回應非常糟糕時選擇重新生成回應(強負面)
回饋可以是顯式或隱式的。顯式回饋是使用者在產品請求時提供的信息;隱式回饋是從使用者互動中學到的,而不需要使用者刻意提供回饋。程式碼助手和 Midjourney 是隱式回饋的例子,而點讚和倒讚是顯式回饋。如果我們設計的 UX 良好,就可以收集大量隱式回饋來改進我們的產品和模型。
2.3.3 需求的優先順序非常重要
打造產品時,我們需要考慮以下需求:
可靠性:99.9% 的正常運行時間,遵守結構化輸出
無害性:不生成冒犯性、色情或其他有害內容
事實一致性:忠實於提供的上下文,不捏造事實
實用性:滿足使用者的需求和請求
可擴展性:SLA,吞吐量
成本:因為我們的預算不是無限的
其他:安全性、隱私、公平性、GDPR、DMA 等等
如果我們試圖同時解決所有這些需求,我們將永遠無法發佈任何產品。因此需要思考需求的優先程度。這意味著要確定哪些是必要的(例如,可靠性和無害性),沒有這些我們的產品就無法運行或不具可行性。關鍵在於確定最小受喜愛產品(Minimum Lovable Product, MLP)。我們必須接受第一個版本不會是完美的,並且需要發佈後再進行迭代。
2.3.4 根據案例調校風險承受
在決定語言模型和應用程序的審查程度時,應考慮案例與受眾。對於面向客戶的醫療或財務建立聊天機器人,錯誤或不良輸出會造成實際傷害並損害信任,我們需要非常高的安全性和準確性水準。但對於不太重要的應用,如推薦系統,或內部應用如內容分類或摘要,過於嚴格的要求只會拖慢進展,而不會增加太多價值。
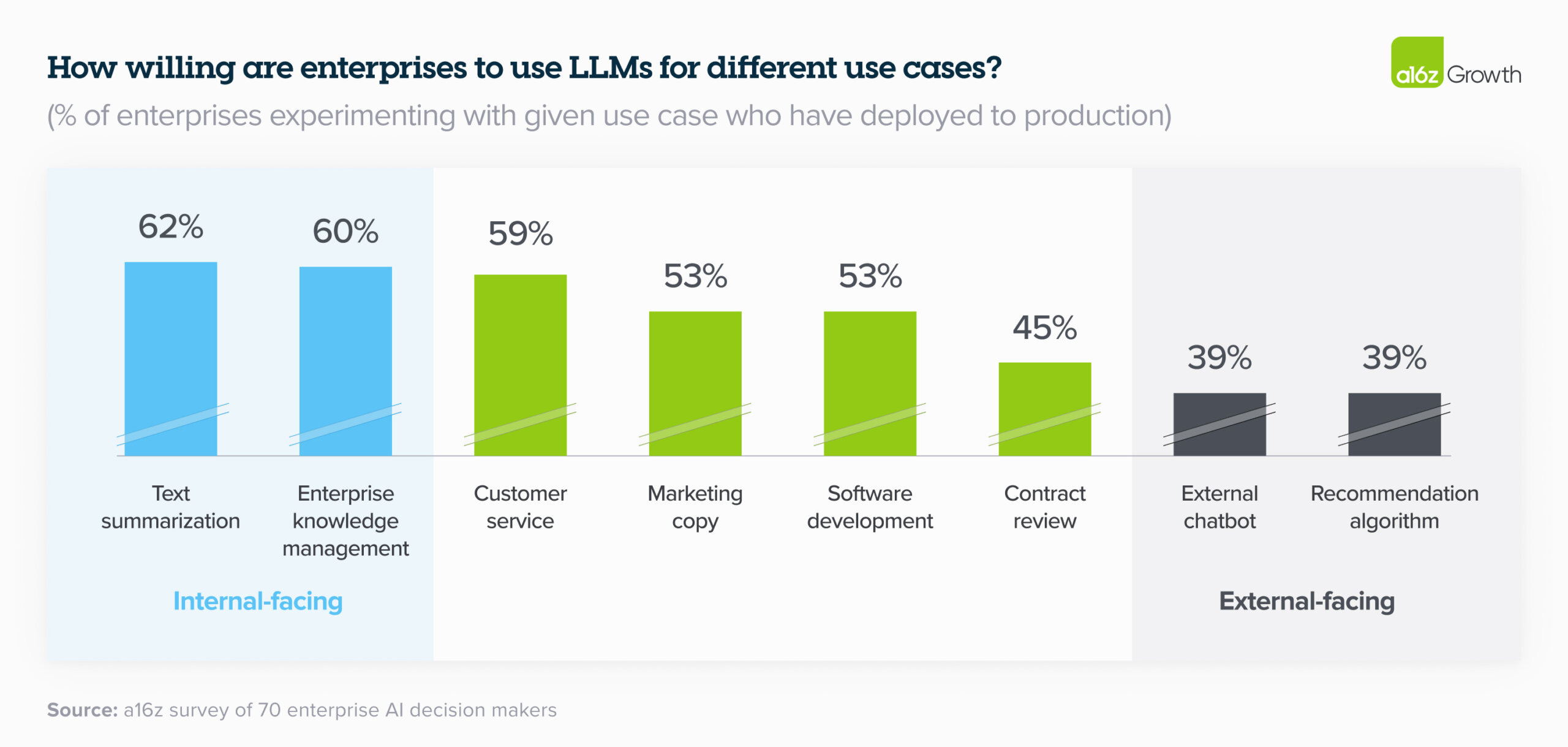
這與最近的a16z報告一致,該報告顯示許多公司在內部 LLM 應用上比在外部應用上進展更快(如下圖所示)。通過對內部生產力進行 AI 實驗,組織可以在更受控制的環境中開始創造價值,同時學習如何管理風險。隨著信心的增加,再來擴展到外部的功能。
2.4 團隊與角色
沒有一個職位是容易定義的,但為這個新領域的工作撰寫職位描述比其他職位更具挑戰性。我們會承認一個新角色的存在——AI 工程師——並討論其地位。重要的是,我們將討論團隊的其他成員以及如何分配責任。
2.4.1 專注於流程,而非工具
面對像 LLM 這樣的新領域時,軟體工程師往往偏愛工具。結果,我們忽略了工具想解決的問題和流程。許多工程師因而承擔了預期之外的複雜性,這對團隊的長期生產力有負面影響。
例如,這篇文章討論了某些工具如何自動創建大型語言模型的提示。它(正確地,依我之見)認為,未先了解問題解決方法或過程而使用這些工具的工程師最終會承擔不必要的技術債。
除了預期之外的複雜性,工具通常規格不明。例如,一個增長的趨勢是隨開即用的 LLM 評估工具,針對有害性、簡潔性、語氣等提供一個泛用的評估。我們見過許多團隊在沒有批判性思考其領域的具體失敗模式的情況下採用這些工具。這與 EvalGen 形成強烈對比。EvalGen 透過深度參與使用者的流程,從定義條件、標註資料到檢查評估,用以創建特定領域的評估系統。使用者流程如下:

EvalGen 引導用戶通過最佳實踐來製作 LLM 評估,即:
定義問題領域的測試(由提示而來)。這些測試可能是測試程式碼的形式或 LLM 評審。
將測試與人類判斷對齊,這樣用戶可以檢查測試是否捕捉到指定的標準。
隨著系統(提示等)的變化迭代測試。
EvalGen 為開發人員提供了評估構建過程的心智模型,而不將其綁定在特定工具上。我們發現,提供 AI 工程師這些背景知識後,他們往往會選擇更精簡的工具或自行建造工具。
除了提示編寫和評估之外,還有太多的 LLM 組件無法在此詳盡列出。然而,AI 工程師在採用工具之前,理解過程是非常重要的。
2.4.2 持續實驗
機器學習產品與實驗有緊密的關係。這裡的實驗不只是 A/B 測試、隨機對照試驗,還包括盡可能小幅度的、頻繁的進行系統中的組件調校,以及離線評估等。大家對評估如此關注的原因並不只是可信度和信心,而是為了能夠更有依據的進行實驗!你的評估越好,你就能越快地迭代實驗,從而越快地趨近系統的最佳版本。
解決相同問題時嘗試各種不同的方法是很常見的,因為現在實驗成本非常低。收集資料和訓練模型的高成本被最小化了——提示工程的成本不過是人力時間。讓你的團隊學習提示工程的基礎。這鼓勵每個人進行實驗,幫助整個組織產生更多樣化的想法。
此外,實驗除了是探索的方式,還能發現新方法!有一個新任務的可行版本嗎?考慮讓團隊中的其他人用不同的方法來解決它,試著找出更好的解法。研究像思維鏈或少樣本這樣的提示技術以提高品質。如果發現你的工具限制了實驗,重建它,或者購買更好的工具。
最後,在產品/專案規劃期間,預留建造評估及運行多個實驗的時間。想想工程產品的產品規格,但要在其中添加明確的評估標準。在制定路線圖時,不要低估實驗所需的時間——在達到上線標準前,預期會進行多次開發與評估的迭代。
2.4.3 賦予每個人使用新 AI 技術的能力
隨著生成式 AI 的普及,我們希望整個團隊——不僅僅是專家——都能理解並有能力使用這項新技術。沒有什麼比實際使用它們更能培養對 LLMs 工作原理(例如延遲、失敗模式、UX)的直覺了。LLMs 相對易於取用:你不需要寫程式就能改善性能,並且每個人都可以通過提示工程和評估產生貢獻。
教育是很重要的一點。它可以從提示工程的基礎開始,使用 n-shot 提示和思維鏈等技術來引導模型生成期望的輸出。那些擁有技術知識的人也可以教導其他人技術方面,例如 LLMs 在生成輸出時是如何自回歸的。換句話說,雖然輸入 tokens 是並行處理的,但輸出 tokens 是按順序生成的。因此,延遲更多地取決於輸出長度而不是輸入長度——這在設計 UX 和設定性能期望時是一個關鍵考慮因素。
我們可以進一步提供動手實驗和探索的機會。也許是一場黑客松?雖然讓團隊花幾天時間在實驗性項目上似乎很高成本,但可能會讓人驚訝的結果。我們知道有一個團隊透過黑客松在一年內幾乎完成了原本估計三年的路線圖。另一個團隊的黑客松透過 LLMs 帶來的火花產生了 UX 上的新典範,這些 UX 現已被優先考慮為來年的重點項目。
2.4.4 別陷入“AI 工程師就是全部”的陷阱
隨著新職位的出現,人們最初往往會誇大與這些角色相關的能力。而當這些工作的實際範圍變得明確時,通常會導致痛苦的修正。剛入行的人以及招聘經理可能會做出誇大的聲明或有過高的期望。過去十年中的顯著例子包括:
資料科學家:“比任何軟體工程師都更擅長統計,比任何統計學家都更擅長軟體工程。”
機器學習工程師(MLE):一種以軟體工程為中心的機器學習觀點
最初,許多人認為僅靠資料科學家就足以完成數據驅動的項目。然而,事實證明,資料科學家必須與軟體和資料工程師合作,才能有效地開發和部署相關產品。
這種誤解在 AI 工程師這個新角色上再次出現,一些團隊認為只需要 AI 工程師即可。事實上,構建機器學習或 AI 產品需要廣泛的專業角色。我們與十多家公司就 AI 產品進行了諮詢,並觀察到他們陷入“AI 工程師就是全部”的陷阱。結果,公司忽視了打造產品所涉及的重要方面,使得產品停留在 POC 階段。
例如,評估和測量對於產品超越氛圍檢查至關重要。有效評估的技能與傳統機器學習工程師的一些優勢相符——僅由 AI 工程師組成的團隊可能缺乏這些技能。共同作者 Hamel Husain 在其最近關於檢測資料差異和領域評估設計的工作中說明了這些技能的重要性。
以下是建構 AI 產品過程中所需角色的大略順序與時間點:
首先,專注於建構產品。這可能包括(或不包含)一位 AI 工程師。AI 工程師在快速原型設計和產品迭代(UX,整合等)方面非常有價值。
接下來,通過監控系統並收集數據來建立確實的基礎。根據數據的類型和規模,你可能需要平台和/或資料工程師。你還必須有系統來查詢和分析這些數據。
接下來,你最終會希望最佳化你的 AI 系統。這不一定涉及訓練模型。基礎包括指標設計、建立評估系統、進行實驗、最佳化 RAG 檢索、不確定性系統的除錯等步驟。MLEs 在這方面非常擅長(儘管 AI 工程師也可以掌握這些技能)。除非你已經完成了前面兩個步驟,否則通常沒有必要僱用 MLE。
除此之外,你自始至終都需要一位領域專家。在小公司,這理想上應該是創始團隊——在大公司,產品經理可以扮演這個角色。了解角色的進展和時間安排至關重要。在錯誤的時間點(例如過早僱用 MLE)招聘人員或以錯誤的順序進行,會浪費時間和金錢,並導致人員流動。此外,在第一和第二階段定期會同 MLE 進行檢查(不一定要全職僱用他們)將有助於打造正確的基礎。
3 策略:使用 LLMs 建構產品且保持領先
成功的產品需要周密的規劃與優先順序,而非無止境的原型設計或追趕最新的模型發佈或趨勢。在這最後一個章節,我們將展望未來,思考建構優秀 AI 產品的策略考量。我們還將探討團隊將面臨的關鍵取捨,例如何時自行建構及何時付費外包,並提出一個早期 LLM 應用發展策略的腳本。
3.1 在找到產品市場契合 (PMF) 之前不要擁有 GPU
要成為優秀的產品,你的產品需要的不僅僅是另一支 API 的代理。但另一個極端的可能更加昂貴與錯誤。過去一年,資本大量湧入,包括一個令人瞠目結舌的 60 億美元的 A 輪融資,用於訓練和自訂模型,卻沒有明確的產品願景或目標市場。在本節中,我們將解釋為什麼太快開始訓練自己的模型是一個錯誤,並探討自架模型的角色。
3.1.1 從零開始訓練(幾乎)沒有任何意義
對於大多數組織來說,從零開始預訓練 LLM 是一種偏離產品開發的分心行為。
儘管這很令人興奮,而且看似每個人都在這樣做,但開發和維護機器學習基礎設施需要大量資源。這包括收集數據、訓練和評估模型以及部署它們。如果你仍在驗證產品市場契合度,這些工作將會分散你開發核心產品的資源。即使你擁有計算能力、數據和技術實力,預訓練的 LLM 可能在幾個月內就會過時。
例如 BloombergGPT,一個專門為金融任務訓練的 LLM。這個模型在 3630 億個 tokens 上進行了預訓練,由 九名全職員工(四名來自 AI 工程部門,五名來自 ML 產品和研究部門)通過英勇的努力完成。儘管如此,它在不到一年的時間裡就被 gpt-3.5-turbo 和 gpt-4 超越。
這類故事表示對於大多數實際應用,從零開始預訓練 LLM,即使是你擁有特定領域的資料,也不一定是最佳資源利用方式。相反,團隊最好是對最強的開源模型進行微調,以滿足他們的具體需求。
當然也有例外。Replit 的程式碼模型 是一個成功案例,專門為程式碼生成和理解進行訓練。Replit 能夠超越其他更大尺寸的模型如 CodeLlama7b。但隨著其他越來越強大的模型的推出,想保持實用性就需要持續的投資。
3.1.2 在證明必要性之前不要進行微調
許多組織進行微調是由於 FOMO(害怕錯過)而不是明確的戰略思考所驅動。
過早地投資於微調,試圖擊敗“只是另一個 API 代理”的指控。事實上,微調是重兵器,只有在你收集了大量案例並證明其他方法無法滿足需求之後,才應部署微調。
一年前,許多團隊告訴我們他們對微調感到興奮。少數團隊找到了產品的契合市場,多數後悔他們的決定。如果你要進行微調,你最好非常有信心能在基礎模型改進時再次進行微調——請參見下面章節的 “模型不是產品”和“建置 LLMOps”。
什麼時候微調可能是正確的選擇?如果案例需要的資料不存在現有模型的訓練資料集中——並且你已經建構了一個 MVP(最小可行產品)證明現有模型是不足的。但要思考你要從哪獲得你所需要的訓練資料。
由 LLM 驅動的應用程序不是科學展覽項目。對它們的投資應與它們對企業戰略目標和競爭優勢的貢獻相符。
3.1.3 從呼叫 API 開始,但不要害怕自架
有了 LLM API,新創公司比以往更容易採用和整合語言模型功能,而無需從零開始訓練自己的模型。Anthropic 和 OpenAI 等提供商提供通用的 API,只需幾行程式碼即可讓你的產品來點 AI。透過這些服務,你可以專注於為客戶創造價值——更快地驗證想法並迭代以找到契合市場的產品。
但是,與資料庫一樣,並不是大家都是合自架,尤其是在規模和需求增加時。當然,自架可能是唯一能在不將機密/私人數據發送出網絡的情況下使用模型的方法,這在受監管行業如醫療保健和金融領域,或由合同義務或保密要求所需的情況下尤為重要。
此外,自架可以避開 LLM 服務供應商施加的限制,如速率限制、舊模型棄用和使用限制等。此外,自架使你能夠完全控制模型,從而更容易圍繞模型打造一個專屬的高品質服務。最後,自架,尤其是模型的微調,可以在大規模時降低成本。例如,Buzzfeed 分享了他們如何微調開源 LLMs 以將成本降低 80%。
3.2 迭代出卓越產品
要長期保持競爭優勢,你需要超越模型,思考什麼能讓你的產品脫穎而出。雖然執行的速度很重要,但它不應該是你唯一的優勢。
3.2.1 模型不是產品,系統整體才是
對於那些不建構模型的團隊來說,創新速度的快速進步是一個福音,因為他們可以從一個最先進的模型遷移到下一個,追求在上下文大小、推理能力和性價比方面的提升,以構建更好的產品。這種進步既令人興奮又可預測。但這也意味著模型可能是系統中最常變動的元件。
因此,將你的精力集中在可以持續提供價值的地方,例如:
評估:可靠地測量各個模型在你的任務上的性能
防護措施:無論模型如何,都能防止期望之外的輸出
快取:避免直接存取模型來減少延遲和成本
資料飛輪:推動上述所有內容的迭代改進
這些元件比模型的本身創造了更深的產品品質護城河。
要注意在應用層建構不是沒有風險的。就模型層面來說,OpenAI 或其他模型供應商想踏進應用端會比你來的容易得多。
例如,一些團隊投資於建造工具來驗證專有模型的結構化輸出;在這方面的深入投資並不是明智的時間利用。OpenAI 需要確保當你請求函數呼叫時,你能得到有效的函數呼叫——因為他們的所有客戶都需要這一點。服務使用者可以在這裡“戰略性拖延”,先打造絕對需要的東西,並等待服務供應商把服務變得更為完整方便使用。
3.2.2 從小處開始建立信任
一個試圖迎合所有人的產品注定會變得平庸。要創建引人注目的產品,公司需要專注於構建能夠吸引使用者反覆使用的體驗。
一個目標在回答用戶任何問題的通用 RAG 系統,缺乏專業化代表該系統無法決定訊息的優先順序、解析特定領域的格式或理解特定任務的細微差別。結果是使用者會感到體驗淺薄且不可靠,無法打到痛點,從而導致流失。
為了解決這個問題,請專注於設定的領域和案例以縮小範圍並深入探索。這有助創建使用者有感的特定領域工具,同時使你能夠坦誠面對系統的能力和限制。清楚表明系統能做什麼和不能做什麼,展現產品對自己的了解程度,幫助用戶了解它在哪些方面可以提供價值,從而建立對輸出的信任和信心。
3.2.3 建置 LLMOps,但要為正確的理由:更快的迭代
DevOps 的本質不是關於可重現的工作流程,跟任務左移或兩個披薩也沒有關係——當然更不是關於撰寫 YAML 文件。
DevOps 的核心在於縮短工作與其結果之間的回饋週期,從而持續改進而不是持續錯誤。其根源可以追溯到精實創業,再到精實製造和豐田生產系統,其重點是單分鐘換模(SMED)和改善(Kaizen)。
MLOps 已將 DevOps 的形式套用於機器學習。我們有可重現的實驗,也有使模型構建者能夠發佈的全套工具。(天哪,我們確實有很多 YAML 文件。)
但作為一個行業,MLOps 沒有如 DevOps 般的作用。它沒有縮短模型與其推理和交互之間的回饋差距。
令人鼓舞的是,LLMOps 領域已經從提示管理這些小問題轉向阻礙迭代的難題:監控、評估與持續改善。
目前,我們已經有了中立、群眾來源的聊天和程式碼模型評估的互動平台——一個集體、迭代改進的外部循環。像 LangSmith、Log10、LangFuse、W&B Weave、HoneyHive 等工具,不僅承諾收集和整理系統產出的資料,還通過深度整合開發來利用這些資料改進系統。你可以選擇採用這些工具或建構自己的。
3.2.4 別作買得到的 LLM 功能
大多數成功的企業並不是 LLM 企業。同時,大多數企業都有機會通過 LLM 來改進。
這觀察常常誤導人們倉促地將系統與 LLM 進行整合改造,增加成本並降低品質,並將它們作為名不符實的 “AI功能” 發佈,搭配令人恐懼的閃耀圖示。更好的方法是:專注於真正與你的產品目標一致並增強核心運營的 LLM 應用程序。
這些是浪費你團隊時間的錯誤嘗試:
為你的企業建造自制的 text-to-SQL 功能。
建造一個與你的文檔對話的聊天機器人。
將公司的知識庫與你的客戶服務聊天機器人整合。
儘管上述是 LLM 應用程序的入門項目,但對於產品公司來說,自己建造這些項目並不合理。這些是許多企業的常見(且複雜,具有高度專業的)問題,應該交由專業的服務處理。將寶貴的研發資源投入到許多人在處理的問題紅海上是一種浪費。
如果這聽起來像陳詞濫調的商業建議,那是因為在當前炒作浪潮的激動中,很容易將任何 LLM 誤認為是新潮、有價值的差異化,忘了哪些應用存在已久。
3.2.5 人工智慧為輔,人類為主
目前基於 LLM 的應用仍然脆弱。它們需要大量的安全防護和防禦性工程,但仍然難以預測。當範圍嚴格限定時,它們可以非常有用。這意味著 LLM 是加速使用者工作流程的極佳工具。
雖然用 LLM 的應用完全取代工作流程或代替人類職務的想法是很誘人的,但目前最有效的模式是人機共生模式(如半人馬象棋)。當能幹的人類結合有能力的 LLM 時,工作效率和完成任務的滿意度會大大提高。GitHub CoPilot 是 LLM 的旗艦應用之一,展示了這些工作流程的力量:
“總體而言,開發人員告訴我們,使用 GitHub Copilot 和 GitHub Copilot Chat 寫程式比不使用它們時更容易、更少錯誤、更可讀、更有重用性、更簡潔、更易維護且更具彈性,寫程式變得更加簡單。” - Mario Rodriguez,GitHub
對於那些在機器學習領域工作了很長時間的人,你們可能會聯想到 “人機循環(Human-In-The-Loop, HITL)” 的概念,但別太快下結論:HITL 是一種基於人類專家確保機器學習模型按預期運行的模式。雖然與此相關,但我們在這裡提出的是更微妙的東西。當前,LLM 驅動的系統不應該是大多數工作流程的主要推動力,它們應該只是資源。
以人類為中心,並詢問 LLM 如何幫助他們的工作流程,這會導致顯著不同的產品和設計決策。最終,你的產品將與那些什麼都交給 LLM 的競爭對手完全不同;這些產品更好、更有用且風險更小。
3.3 從提示工程、評估和資料收集開始
讓我們思考最初會遇到的問題:如果一個團隊想要構建一個 LLM 產品,應該從哪裡開始?
在過去的一年看過許多的案例,我們確信成功的 LLM 應用遵循著相似的軌跡。本章節我們將介紹這個基本的 “入門” 指南。其核心概念是從簡單開始,僅在需要時增加複雜性。合理的原則是,每個複雜度級別通常需要比前一級別多至少一個數量級的努力。考慮到這一點…
3.3.1 提示工程優先
從提示工程開始。使用我們在戰術部分討論過的所有技術。思維鏈、n-shot 提示和結構化輸入輸出幾乎總是會產生效用。先用最強大的模型進行原型設計,再嘗試降級,從較弱的模型中擠出性能。
只有當提示工程無法達到所需的性能時,才應考慮進行微調。一些非功能性要求(例如,隱私、完全控制、成本)可能讓第三方模型的使用變得不可行,並因此需要自架。記得確認這些隱私要求不會阻礙你利用使用者資料進行微調即可!
3.3.2 構建評估並啟動數據飛輪
即使是剛剛起步的團隊也需要評估。否則,你無法知道你的提示工程是否足夠,或者你的微調模型何時準備好替換基礎模型。
針對你的任務設計有效的評估,並反映預期的案例。我們建議的第一級評估是單元測試。這些簡單的測試能夠檢測已知或假設的失敗情境,並輔助設計決策。另外可參考其他針對特定任務例如分類、摘要等的評估系統。
雖然單元測試和基於模型的評估很有用,但它們不能取代人工評估。讓人們使用你的模型/產品並提供回饋。這既能測量產品的性能和缺陷率,又能收集高品質的標註資料,這些資料可以用來微調未來的模型。這創建了一個正回饋循環,或資料飛輪,隨著時間的推移不斷增強:
人工評估來衡量模型性能與發現缺陷
使用標註資料來微調模型或更新提示
重複此過程
例如,在審核 LLM 生成的摘要時,我們可能會對每個句子進行詳細的回饋,標註其事實不一致、無關緊要或風格不佳。我們可以使用這些事實不一致標註來訓練一個幻覺分類器,或者使用相關性標註來訓練一個相關性獎勵模型。另一個例子是,LinkedIn 分享了他們成功使用基於模型的評估系統來判別幻覺、AI 違規、連貫性等方面的情況。
評估系統是隨時間增值的資產,打造與維護此系統不僅是純粹的運營費用,應視為更高一級的戰略投資,並在此過程中建立我們的資料飛輪。
3.4 低成本認知的高層次趨勢
1971 年,Xerox PARC 的研究人員預測了一個個人電腦透過網路連結的未來。他們在許多技術發明中扮演關鍵角色,如乙太網路、圖形介面、游標與視窗等,催生了這樣的未來。
他們也觀察非常有用但尚不經濟的應用(如因為記憶體價格而過於昂貴的影片),然後查看該技術的歷史價格趨勢(例如摩爾定律),並預測這些技術何時會變得經濟。
我們也可以對 LLM 技術進行同樣的操作,儘管我們沒有像電晶體價格那樣乾淨直接的數據。我們可以用熱門且既存的標準,如 Massively-Multitask Language Understanding 資料集,並使用一致的輸入方法(five-shot)。即可看出隨著時間推移,運行不同性能級別的語言模型的成本。

自從 OpenAI 的 davinci 模型作為 API 推出以來的四年裡,在這個任務上運行具有相同性能的模型的成本從每百萬個詞塊(約等同一百篇這篇文章)20美元降至 10 美分以下,這相當於每六個月成本減半。同樣,截至 2024 年 5 月,通過 API 提供者或自行運行 Meta 的LLaMA 3 8B 的成本僅為每百萬詞塊 20美分,其性能類似於 OpenAI 的 text-davinci-003(ChatGPT 初期的基礎模型)。該模型在 2023 年 11 月底發布時,每百萬詞塊的成本約為 20 美元。在短短 18 個月內下降了兩個數量級,而摩爾定律在同一時間則是增加一倍。
現在,讓我們想想非常有用但尚不經濟的 LLM 應用(如生成性電玩角色,見Park等人的論文),其成本估計為每小時 625 美元(見此處)。自該論文於 2023 年 8 月發表以來,成本大約下降了一個數量級,降至每小時 62.50 美元。我們可以預期它在九個月內降至每小時6.25美元。
相對的,當電玩《小精靈》在 1980 年推出時,今天的一美元可以玩一次,每小時大約可以玩六次,6 美元。這個簡單計算顯示,LLM 增強遊戲體驗將在2025年某個時候變得經濟實惠。
這些趨勢是新的,只有幾年歷史。但在未來幾年內,這一過程減速的可能性很小。即使我們可能用盡了演算法和資料集中的容易摘採的果實,例如超過 “絨鼠比率” 約每參數 20 個詞塊,硬體上的創新與投資有望彌補這一不足。
由此可知今天完全不可行的展示或研究論文將在幾年內成為進階功能,然後迅速變成一般商品。因此當我們建構系統和組織時,應該考慮到這點非常重要的戰略事實。
4 從 0 到 1 的原型展示已經夠了,現在是從 1 到 N 的產品時刻
我們明白,建造 LLM 原型展示非常有趣。只需幾行程式碼、一個向量資料庫和一個精心設計的提示,我們就能創造✨魔法✨。在過去的一年裡,這種魔法就是新時代的網際網路、智慧手機,甚至印刷術。
不幸的是,在受控環境下運行的原型展示和能夠可靠地大規模運行的產品之間有著天壤之別。
有一大類問題,想像並建構原型展示很容易,但製作成產品卻非常困難。例如,自動駕駛:展示一輛車在街區自動駕駛很容易;將其製作成產品需要十年。 - Andrej Karpathy
以自動駕駛汽車為例。第一輛由神經網絡驅動的汽車出現在1988年。二十五年後,Andrej Karpathy 首次在Waymo中進行演示。十年後,該公司獲得了無人駕駛許可證。從原型到商業產品,這需要三十五年的嚴格工程、測試、完善和監管導航。
在業界和學術界,我們在過去一年裡觀察到了起伏。我們希望從戰術面如評估、提示工程和防護措施到營運面的技術和團隊建設,再到策略面視角如哪些能力需要內部建構。我們希望我們所學到的經驗教訓能夠在之後也能幫助到你們,讓我們一起在這項令人興奮的新技術上繼續前進。